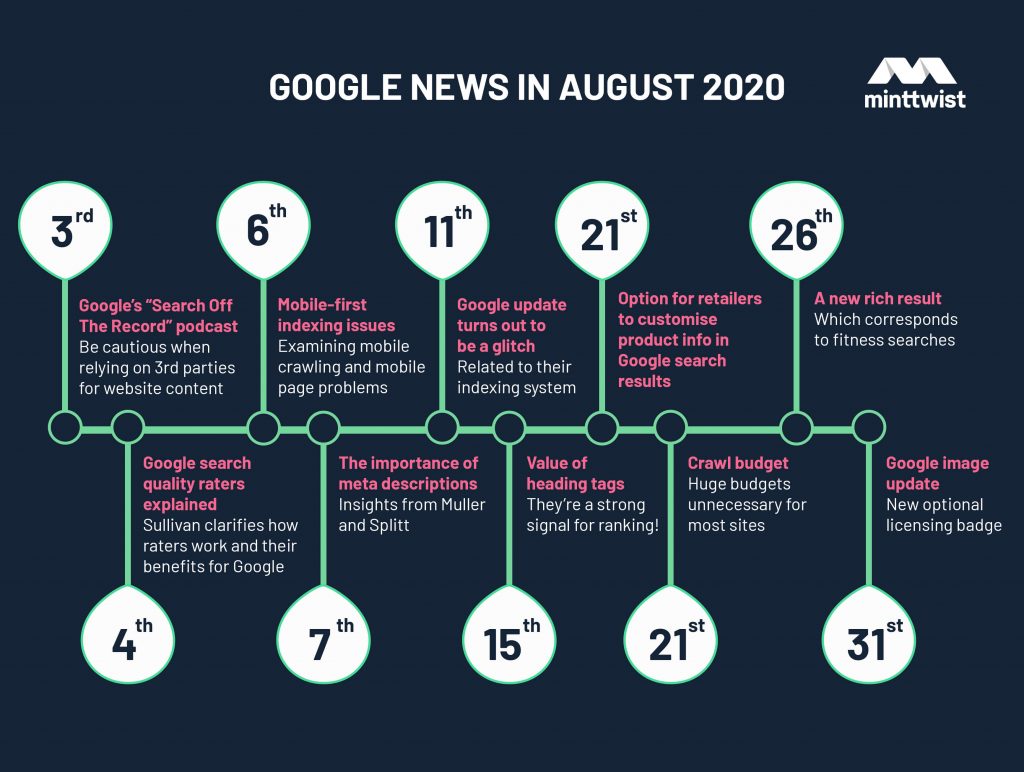
Aggiornamenti Google da agosto 2020
Google è stato ancora una volta particolarmente impegnato, sviluppando strumenti e condividendo approfondimenti con la comunità. In questi articolo vedremo quali sono stati gli aggiornamenti di Google da agosto 2020. I sostenitori della SEO hanno seguito l’esempio, aiutando le aziende a facilitare eventuali aggiornamenti e funzionalità dei motori di ricerca che potrebbero avvantaggiarli a lungo termine.
Mentre la mobilità delle persone sembra essere più limitata, l’industria del turismo si trova in una situazione di stallo. Ciò ha inevitabilmente dato spazio a una crescita senza precedenti del settore e-commerce. La tecnologia rende i prodotti più economici e le persone tendono ad acquistare i prodotti necessari e convenienti.
Ovviamente, Google lo sa bene e intorno a metà agosto ha creato più opzioni per i rivenditori per avere un controllo migliore su come le informazioni sui prodotti vengono visualizzate nei risultati di ricerca. A parte questo, Google ha subito un problema tecnico di indicizzazione che ha scosso la qualità della ricerca in tutto il mondo, ma che è durato non più di poche ore.
COMINCIA ORA LA TUA DIGITAL STRATEGY
Contattaci subito per una prima consulenza gratuita
3 agosto – Podcast “Cerca nel registro” di Google
Martin Splitt di Google richiama l’attenzione dei webmaster sui potenziali aspetti negativi dell’utilizzo di contenuti JavaScript resi da terze parti. Ha usato le sezioni dei commenti del blog come esempio.
In quella sessione di podcast di inizio agosto, Splitt ha aperto questo argomento sullo sfondo di un problema che si è verificato il mese precedente, quando Google non indicizzava i commenti del blog di un fornitore di contenuti di terze parti chiamato Disqus.
I fornitori di terze parti, come Disqus, distribuiscono contenuti incorporati utilizzando JavaScript che a sua volta viene visualizzato sul lato client. Anche se questo incidente era dovuto a un problema tecnico da parte di Google, ha scatenato una discussione più ampia su come gestire i contenuti JavaScript critici resi da fornitori di terze parti.
“Perché la sfida è che tu, come proprietario di un sito web, non hai realmente il controllo su una terza parte. E se utilizzi JavaScript lato client per inserire contenuti di terze parti nel browser, le cose possono andare storte. Potrebbero robotizzare la loro API JavaScript e quindi non possiamo effettuare la richiesta o forse i loro server sono davvero sotto carico. E poi decidiamo di non fare queste richieste a terze parti perché stanno già sperimentando situazioni di carico elevato”. –
Martin Splitt, Developer Advocate di Google.
Splitt ha continuato dicendo che questo problema può essere affrontato facendo tutto sul lato server, spiegando che se la terza parte ha un’API con cui puoi interagire dal lato del client. Rispondendo alla domanda di John Mueller se è una cattiva idea affidarsi a terze parti, Splitt ha risposto “è più che un’idea giusta affidarsi a terze parti“. Splitt ha aggiunto che “dobbiamo capire che abbiamo poco controllo su ciò che accade nel browser e abbiamo meno controllo quando ci affidiamo a Googlebot per essere essenzialmente il capofamiglia, piuttosto che quando il tuo server sta facendo il lavoro per te”.
4 agosto – I valutatori della qualità della ricerca di Google non influenzano direttamente le classifiche
Google ha pubblicato una spiegazione completa su come le modifiche alle classifiche di ricerca vengono valutate internamente prima di essere comunicate agli utenti.
Danny Sullivan, referente pubblico di Google per la ricerca, è a capo del team dei cosiddetti valutatori della qualità della ricerca che sono le persone le cui valutazioni vengono prese in considerazione per i famigerati aggiornamenti degli algoritmi.
In parole semplici, i valutatori di ricerca di Google parlano a persone di tutto il mondo e cercano di capire come migliorare la ricerca ed essere più pertinente per loro.
“Questo è il motivo per cui abbiamo un team di ricerca il cui compito è parlare con persone in tutto il mondo per capire come la ricerca può essere più utile. Invitiamo le persone a darci un feedback su diverse iterazioni dei nostri progetti e facciamo ricerche sul campo per capire come le persone in diverse comunità accedono alle informazioni online”. – Danny Sullivan, Ricerca Google.
Riguardo a cosa sono esattamente i valutatori della qualità della ricerca, Danny Sullivan menziona:
“Pubblichiamo linee guida per i valutatori disponibili al pubblico che descrivono in dettaglio come i nostri sistemi intendono far emergere contenuti di qualità. Queste linee guida sono lunghe più di 160 pagine, ma se dobbiamo ridurle a una semplice frase, ci piace dire che la ricerca è progettata per restituire risultati pertinenti dalle fonti più affidabili disponibili”.
È fuor di dubbio che l’algoritmo può raccogliere segnali in automatico, ma la pertinenza e l’affidabilità richiedono un giudizio umano.
Pertanto, Google impiega 10.000 valutatori della
qualità della ricerca da tutto il mondo per aiutare la causa.
I valutatori aiutano Google a capire come le persone sperimentano i risultati di ricerca. Le valutazioni sono progettate in base alle linee guida di Google e mirano a ottenere il reale sentimento degli utenti e il tipo di informazioni di cui hanno veramente bisogno.
Sullivan ha continuato spiegando come funzionano i valutatori della qualità della ricerca. È interessante notare che Google conduce una sorta di test SERP A/B. Google assegna una serie di query a gruppi di valutatori, mostrando loro due versioni delle pagine dei risultati di ricerca.
Una è la versione attuale e l’altra è considerata una versione migliorata agli occhi di Google. Ogni pagina dei risultati viene valutata rispetto alla query, sempre in base alle linee guida del valutatore.
Per valutare la E-A-T, che sta per competenza, autorità e affidabilità, i valutatori stanno conducendo ricerche reputazionali sulle fonti.
Al termine della ricerca, i valutatori forniscono una valutazione di qualità per ogni pagina. Detto questo, Sullivan ha chiarito che le valutazioni non influiscono direttamente sulle classifiche, ma piuttosto aiutano Google a misurare quanto correttamente i contenuti vengono consegnati agli utenti.
“È importante notare che questa valutazione non influisce direttamente sul posizionamento della pagina o del sito nella ricerca. Nessuno decide che una determinata fonte è “autorevole” o “affidabile”. In particolare, alle pagine non vengono assegnate valutazioni per determinare il livello
di classificazione”. – Danny Sullivan, Ricerca Google.
COMINCIA ORA LA TUA DIGITAL STRATEGY
Contattaci subito per una prima consulenza gratuita
6 agosto – Martin Split spiega come risolvere i problemi di indicizzazione mobile first in un episodio di Lightning Talks
Le restrizioni sugli eventi di persona hanno costretto Google ad adattarsi al nuovo panorama, quindi Martin Splitt ha dovuto fare questa presentazione da solo e durante le solite conferenze per webmaster di Google.
In un’implementazione di Lightning Talks a prova di Covid-19, Martin Splitt ha affrontato l’argomento cruciale dell’indicizzazione mobile-first spiegando quali sono i problemi comuni e fornendo soluzioni specifiche.
Risulta che i problemi più comuni che derivano dall’indicizzazione mobile-first sono:
- Problemi di scansione sui dispositivi mobili.
- Problemi di contenuto della pagina mobile.
È interessante notare che i sui dispositivi mobili si verificano essenzialmente quando Google esegue la scansione con la versione mobile di Googlebot.
In questo caso, una richiesta può essere gestita in modo diverso dal server in base al programma utente. Quando accade qualcosa del genere, Google non è in grado di ottenere informazioni sufficienti dalle pagine.
Ciò si traduce in segnali insufficienti per consentire a Google di mostrare qualsiasi pagina nei risultati di ricerca.
I problemi di contenuto della pagina mobile si verificano principalmente quando un sito offre contenuti diversi rispetto alle versioni mobile e desktop.
Meno informazioni significa che Google non può determinare se una pagina è pertinente, quindi il sito non può essere classificato correttamente nei risultati di ricerca.
Per evitare di incontrare tali problemi, Splitt suggerisce quanto segue.
Da non fare:
- Dlock Googlebot dalla scansione con una direttiva “Disallow” nel file robots.txt
- Utilizzare il meta tag noindex
- Impedire a Googlebot di eseguire la scansione dei CSS per dispositivi mobili
- Impedire a Googlebot di seguire i link interni
Da fare:
- Direttive Robots.txt
- Tag noindex e nofollow
- La capacità di scansione del server
Le scansioni dei desktop del server dovrebbero essere tante quante le scansioni dei dispositivi mobili. Splitt ha sottolineato che il contenuto della pagina mobile dovrebbe essere identico alla versione desktop.
Ad esempio, se nella versione della tua pagina mobile gli utenti vedono il pulsante “Vedi altro” mentre questo pulsante non esiste nella versione desktop e tutto il contenuto è visibile sulla pagina, questo può rappresentare un problema.
Poiché Googlebot esegue la scansione solo di ciò che vede come visibile e non interagisce con gli elementi della pagina, i contenuti della tua pagina per dispositivi mobili non verranno classificati correttamente.
Mantieni identici i contenuti per dispositivi mobili e desktop per evitare problemi di indicizzazione al primo posto. Non tenere nulla fuori dalla vista di Googlebot, inclusi dati strutturati e meta descrizioni.
7 agosto – Le meta descrizioni funzionano come un riepilogo dei contenuti che aiutano Google a capire cosa è importante in una pagina
Una delle poche cose che sembra essere ampiamente accettata nella comunità di ricerca è che la meta descrizione non è un fattore di ranking e ha un valore SEO basso. Ma è così?
In risposta a un thread di Twitter, Martin Splitt di Google ci ha fornito un prezioso suggerimento su come Google interpreta le meta descrizioni.
Split dice chiaramente che l’elemento HTML della meta descrizione aiuta Google a capire di cosa tratta il contenuto della pagina. John Muller chiarisce che le meta descrizioni non sono un fattore di ranking.
Tuttavia, Mueller non sembrava aggiungere nulla alla spiegazione di Martin. Ciò che è interessante è che l’elemento del titolo è stato ampiamente percepito come un fattore di ranking e la meta descrizione agisce come la descrizione del tag title che riassume di cosa tratta una pagina.
Da un certo punto di vista, Splitt sembra implicare che la meta descrizione svolga un ruolo simile all’elemento del titolo, fornendo effettivamente un blurb che descrive in dettaglio di cosa tratta una pagina.
Questo è leggermente diverso da ciò che la maggior parte di noi aveva in mente per quanto riguarda la meta descrizione e il contributo di Mueller alla discussione non sembra chiarire molto.
Il tempo ci dirà se Splitt stava suggerendo qualcosa che sembrerebbe un’intuizione molto preziosa.
11 agosto – Un presunto massiccio aggiornamento di Google si è rivelato un enorme problema di indicizzazione
La comunità di ricerca pensava che un aggiornamento fondamentale si stesse svolgendo inaspettatamente davanti ai loro occhi, ma in realtà non era altro che un problema tecnico.
Poche ore dopo, l’account Twitter dei webmaster di Google ha dato spiegazioni a riguardo. Gary Illyes di Google è intervenuto nella discussione spiegando come funziona l’indice di Caffeine con un elenco.
Alcuni anni fa, Google aveva sviluppato un sistema di scansione e indicizzazione del web chiamato Caffeine. L’obiettivo era un sistema completo che elabora i dati più velocemente, indicizza l’intero web in tempo reale e scala nel tempo. Tuttavia, Gary Illyes ha spiegato anche gli aspetti negativi.
Da qui si è alzato un polverone attorno al problema e presto è apparso evidente che l’impatto del glitch si faceva sentire su tutta la linea.
Il problema tecnico della ricerca di Google era molto diffuso e interessava tutte le lingue e tutte le nicchie. Risultati di ricerca scadenti e fluttuazioni nelle classifiche sono stati osservati da tutti, dai siti di e- commerce agli esperti di ricerca.
Il membro di WebmasterWorld Whoa182 ha aggiunto nella discussione più ampia con: “Che diavolo sta succedendo? Ho appena notato che i miei articoli sono passati dalla pagina 1 alla pagina +. Sembra sia successo nelle ultime ore! Molti dei miei concorrenti sono tutti scomparsi dalle SERP“.
E poi aggiunge: “Ok, sono solo enormi fluttuazioni nelle posizioni della pagina. Un minuto è a pagina 1, poi a pagina 7 o qualsiasi altra cosa, e poi di nuovo“.
Gli esperti di webmaster di Google Gary Illyes e John Mueller hanno chiarito che il problema tecnico era correlato al sistema di indicizzazione di Google.
Tuttavia, quel problema tecnico ha causato un enorme scossone nei risultati di ricerca che è durato alcune ore, prima che tutto tornasse alla normalità.
15 agosto – John Mueller: i tag delle intestazioni sono un segnale davvero forte
In quell’Hangout Webmaster Central di metà agosto, Mueller ha affermato con sicurezza che i tag di intestazione sono un segnale forte in termini di ranking.
E quando si tratta di testo su una pagina, un’intestazione è un segnale molto forte che dice che questa parte della pagina riguarda questo argomento… che tu lo metta in un tag H1 o un tag H2 o H5 o altro, non ha molta importanza.
Piuttosto questo segnale generale che ci dai che dice “questa parte della pagina riguarda questo argomento. E quest’altra parte della pagina forse tratta di un argomento diverso”. – John Mueller, Senior Webmaster Trends Analyst presso Google.
A John è stato chiesto se una pagina senza un titolo H1 sarà ancora classificata per le parole chiave che sono nel titolo H2.
“I titoli di una pagina ci aiutano a comprendere meglio il contenuto della pagina. Ma non sono l’unico fattore di ranking che abbiamo. Analizziamo anche il contenuto da solo. Ma a volte avere un’intestazione chiara su una pagina ci dà un po’ più di informazioni su ciò di cui tratta quella sezione”. – John Mueller, Senior Webmaster Trends Analyst presso Google.
Ciò che colpisce delle parole di Mueller è che definisce le intestazioni un fattore di ranking mentre in passato ha minimizzato la loro importanza.
“Il tuo sito si posizionerà perfettamente senza tag H1 o con cinque tag H1. Quindi non è qualcosa di cui devi preoccuparti. Alcuni strumenti SEO segnalano questo come un problema e dicono “Oh non hai tag H1 o hai due tag H1” … dal nostro punto di vista non è un problema critico”. – John Mueller, Senior Webmaster Trends Analyst presso Google
Chiunque abbia condotto qualsiasi tipo di analisi della concorrenza sa che le pagine possono classificarsi abbastanza bene senza un’intestazione H1.
Elaborando più dal punto di vista dei contenuti, Mueller non ha lasciato spazio a dubbi confermando che un’intestazione è un segnale forte quando si tratta di fornire informazioni sull’argomento della pagina.
21 agosto: Google offre ai rivenditori la possibilità di personalizzare le informazioni sui prodotti nei risultati di ricerca
Google annuncia tramite il blog centrale del webmaster, che ai rivenditori verranno offerte opzioni per controllare la modalità di visualizzazione delle informazioni sui prodotti nei risultati di ricerca.
I rivenditori possono ora sfruttare i metatag, i robot e gli attributi HTML per controllare il modo in cui i loro prodotti vengono visualizzati nei risultati di ricerca di Google.
Queste nuove funzionalità consentono ai rivenditori di contrassegnare le pagine dei loro prodotti e personalizzare gratuitamente gli snippet di ricerca secondo le loro esigenze e preferenze.
Tuttavia, Google aggiunge che potrebbe includere anche contenuti che non sono stati sottoposti a markup.
Come risultato della frequente scansione dei contenuti, è possibile estrarre attributi alternativi se ritenuti pertinenti.
“Sebbene i processi di cui sopra siano il modo migliore per garantire che le informazioni sul prodotto vengano visualizzate in questa esperienza di ricerca, Google potrebbe anche includere contenuti che non sono stati sottoposti a markup utilizzando schema.org o inviati tramite Merchant Center quando il contenuto è stato sottoposto a scansione ed è correlato. Google fa questo per garantire che gli utenti vedano un’ampia varietà di prodotti da un ampio gruppo di
rivenditori quando cercano informazioni su Google”. – Google.
Google ha anche fornito modi per implementare questi controlli
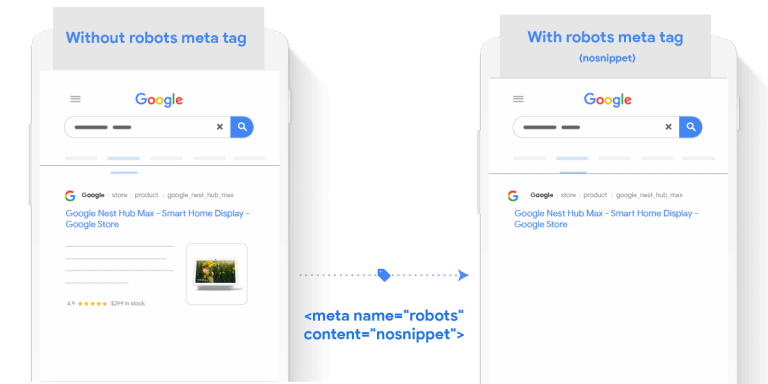
- Utilizzando il metatag “nosnippet” i rivenditori potranno impedire la visualizzazione di testo, immagine e snippet per la pagina nei risultati di ricerca.
Di seguito sono riportate due pagine di prodotto con e senza tag.
Risultati di pagine di Google con meta tag “nosnippet”:
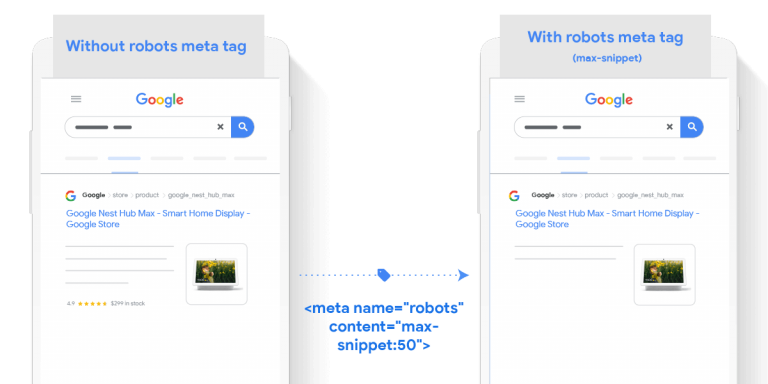
2. Utilizzando “max-snippet: [numero]” i rivenditori di metatag robots possono specificare una lunghezza massima dello snippet, in caratteri e se i dati strutturati sono maggiori della lunghezza massima dello snippet, la pagina verrà rimossa da qualsiasi esperienza di inserzione gratuita.
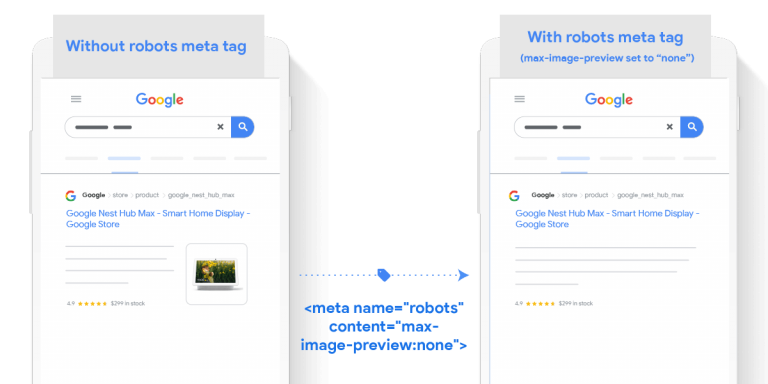
3. Utilizzando “max-image-preview: [impostazione]” i rivenditori del metatag robots possono specificare un’anteprima della dimensione massima dell’immagine da mostrare per le immagini su questa pagina, utilizzando “standard” o “large”.
4. Utilizzando l’attributo HTML “data-nosnippet”, i rivenditori possono specificare una sezione di contenuto che non deve essere inclusa nell’anteprima di uno snippet. Quando questo attributo viene applicato alle informazioni per le offerte (prezzo, disponibilità, valutazioni, immagine) rimuoverà la scheda da qualsiasi esperienza di inserzione gratuita.
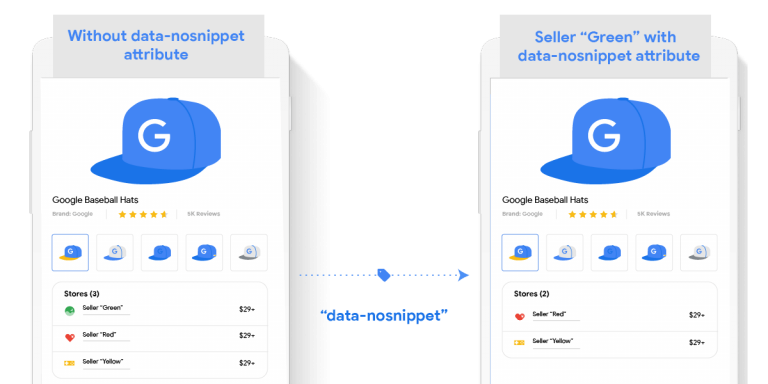
In conslusione, il blog del Centro webmaster di Google fornisce alcune informazioni aggiuntive sulle preferenze del rivenditore.
Queste istruzioni non si applicano alle informazioni fornite tramite il markup schema.org o alla data del prodotto inviate tramite Google Merchant Center.
COMINCIA ORA LA TUA DIGITAL STRATEGY
Contattaci subito per una prima consulenza gratuita

